

Linear regression allows us to model the relationship between variables. This might allow us to predict a future outcome if we already know some information, or give us an insight into what is needed to reach a goal.
To fit a linear regression model, we need one dependent variable, which we will study the changes of as one or more independent variables are changed. As an example, we could model how many goals are scored (dependent variable), as more shots are taken (independent variable). As we have just one independent variable, this is a simple linear regression – models that take in multiple independent variables are are known as multiple linear regressions.
This article is going to apply a simple linear regression model to squad value data against performance in the Premier League. This might help us to see how much a squad might need to invest to avoid relegation, make European spots or to create a data-driven target for our team.
The steps that we are going to take include a quick look & explore of our dataset, creating the model & then making some assessments on the back of it. Then, we’ll calculate a better metric to improve our model. We will use the sklearn module to make this much less intimidating than it might seem right now! Let’s get the modules in place and read in a local dataset called positionsvsValue – which you can download here.
Initial set-up & exploration
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn import metrics
#load data
data = pd.read_csv("positionsvsValue.csv")
data.head()
data.describe()
So we have a 220-row dataset, with each row being a team in each Premier League season since 2008/09. For each of the teams, we get squad sizes, ages, squad value (in Euros) as well as performance data with goal difference, points & position. The values are taken from Transfermarkt (once again, you can find the data here).
Our aim is to get a model together that would help us to predict a team’s points based on their squad value. Before we do that, we should check to see what the relationships are among some of the key variables. Let’s do that visually with a pair plot.
sns.pairplot(data[['Season','GD', 'Squad Value', 'Points', 'Position']])
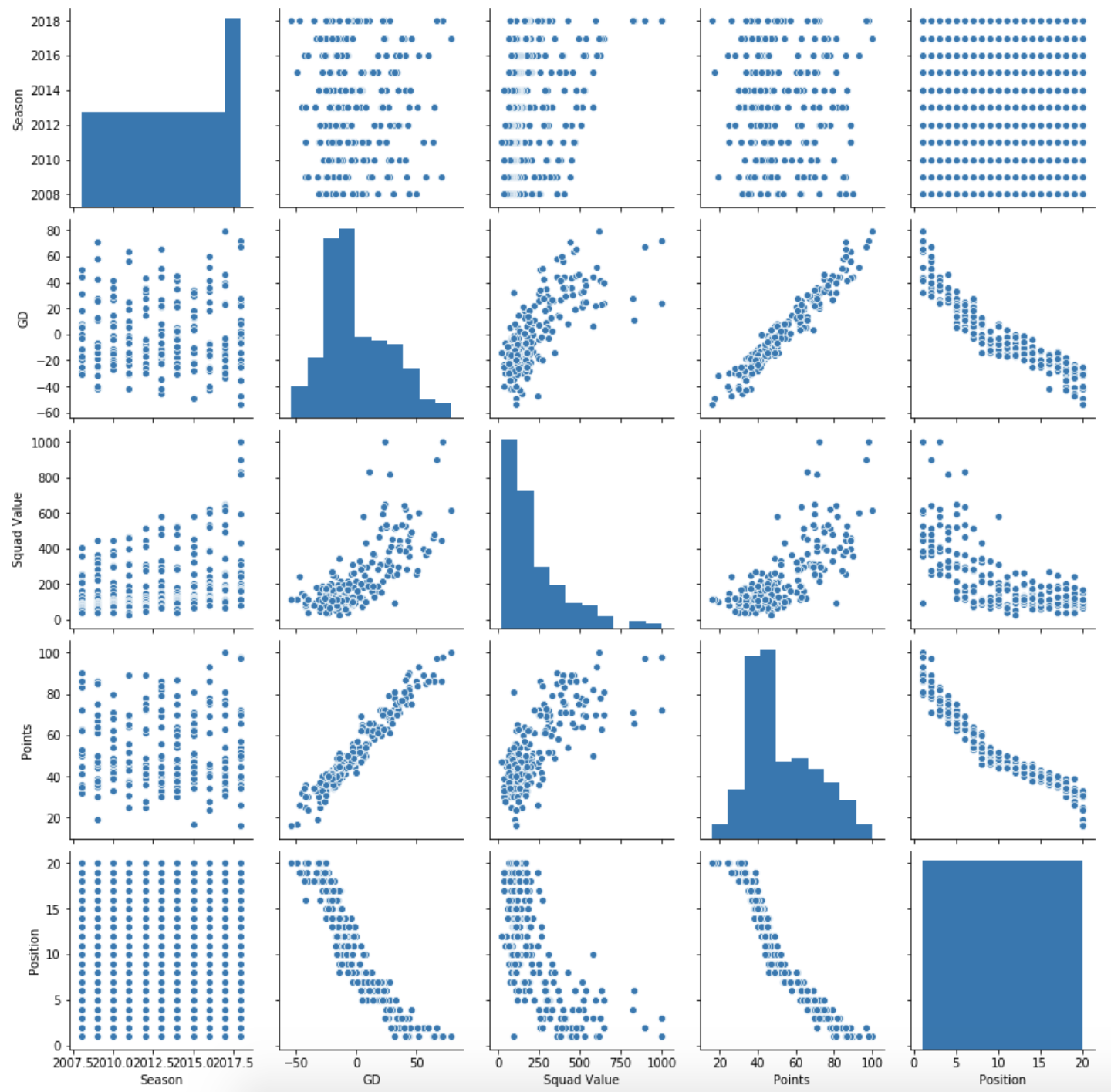
Some interesting points to keep in mind:
- Points & goal difference correlate really strongly, as you might expect.
- Squad value goes up as goal difference and points go up, but as more of a curve than a line.
- Squad value has increased over time (important! We’ll come back to this)
Thinking back to our initial problem – modelling squad value on performance – we need to define what performance is. I think that we can answer this by seeing which of points and position correlate more with squad value. Let’s check if position correlates more than points:
abs(data['Squad Value'].corr(data['Position'])) > data['Squad Value'].corr(data['Points'])
Seemingly not, so for the purpose of the article, we’re going to build our model around how many points you should expect for your squad value, not the position.
Building our Model
So let’s get to it. We’ll take the following steps:
1) Get and reshape the two columns that we want to use in our model: Points & Squad Value
2) Split each of the two variables into a training set, and a test set. The train set will build our model, the test set will allow us to see how good the model is.
3) Create an empty linear regression model, then fit it against our two training sets
4) Examine and test the model
Let’s work through each step
#1- Get our two columns into variables, then reshape them
X = data['Squad Value']
y = data['Points']
X = X.values.reshape(-1,1)
y = y.values.reshape(-1,1)
We can use train_test_split to easily create our training and test sets. There are a few arguments we have to pass, in addition to the variables that will be split. There is test_size, which tells the function what % of the split should be in the test side. Random_state is not necessary, but it sets a starting point for the random number generation involved in the split – if you want your data to look like this tutorial, keep this the same.
#2- Use the train_test_split function to create our training sets & test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=101)
Next up is creating the empty model, then fitting it with our training data. The sklearn package means that this only takes a couple of lines:
lm = LinearRegression()
lm.fit(X_train,y_train)
Holy shit, you’ve just made a linear regression model! Bit of an anticlimax until we do something with it…
The final part is examining the model. This means seeing what conclusions it gives to answer our main question (value -> performance), and importantly, how valid they are.
We can start by checking the coefficient. This is the amount that we expect our response variable (points) to change for every unit that our predictor variable changes (squad value in m Euros). Simply, for every extra million we put into our squad value, how many extra points should we get? We find out with the .coef_ method of the model.
print(lm.coef_)
So on average, an extra million gets you 0.07 points. Looks like we’re going to need an absolute warchest to stay up.
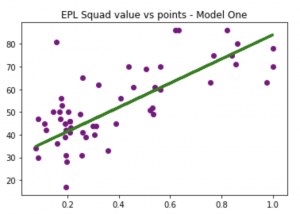
We now need to test the model by checking predictions from the trained model against the test data that we know is true. Let’s check out a few ways of doing this. Firstly, we’ll create some predictions using lm.predict – we’ll feed it the real squad value data, and it will predict the points based on the model. Then we’ll use this in 2 charts, firstly plotting the real data against the prediction line, then plotting the prediction against the true data.
predictions = lm.predict(X_test)
plt.scatter(X_test, y_test, color='purple')
plt.plot(X_test, predictions, color='green', linewidth=3)
plt.title("EPL Squad value vs points - Model One")
plt.show()
plt.scatter(y_test,predictions)

Lots of values that match up well, and lots that don’t. Tough to see how far we are out, though. So let’s get a histogram to plot the differences between the predictions and the true data:
plt.title('How many points out is each prediction?')
sns.distplot((y_test-predictions),bins=50, color = 'purple')
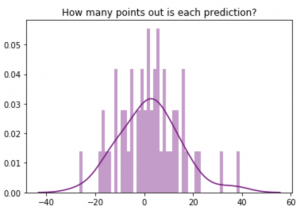
A few where we are way out, like 30-40 points out. But mostly, we are within 10 points or so either way.
We are going to look to improve this, so to help with the comparison let’s use a metric called ‘mean absolute error’. This is simply the average difference between the prediction and the truth. Hopefully, we can reduce this with the next one.
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test, predictions))
Alternatively, we could put these in a table, rather than plot them. But that is a bit less friendly to work through.
df = pd.DataFrame({'Actual': y_test.flatten(), 'Predicted': predictions.flatten()})
df.head()
df['Actual'].corr(df['Predicted'])
Improving the model
When we took an exploratory look at the data, we found that team values had increased over seasons. As such, comparing a 100m squad in 2008 to a 100m squad in 2018 probably isn’t fair.
To counter this, we are going to create a new ‘Relative Value’ column. This will take each team in a season, and divide it by the highest value in that league. These values will be between 0 & 1 and give a better impression of comparative buying power, hence performance in the league. Hopefully it will provide for a better model than the example above.
Let’s create this column as a list, then add it to our dataframe.
#Blank list
relativeValue = []
#Loop through each row
for index, team in data.iterrows():
#Obtain which season we are looking at
season = team['Season']
#Create a new dataframe with just this season
teamseason = data[data['Season'] == season]
#Find the max value
maxvalue = teamseason['Squad Value'].max()
#Divide this row's value by the max value for the season
tempRelativeValue = team['Squad Value']/maxvalue
#Append it to our list
relativeValue.append(tempRelativeValue)
#Add list to new column in main dataframe
data["Relative Value"] = relativeValue
data.head()
Looking good, the 4 teams below Chelsea do indeed have lower squad values, as represented by lower relative values.
Let’s get a pairplot to check out the new column’s relationship with the others.
sns.pairplot(data[['GD', 'Squad Value', 'Relative Value', 'Points', 'Position']])
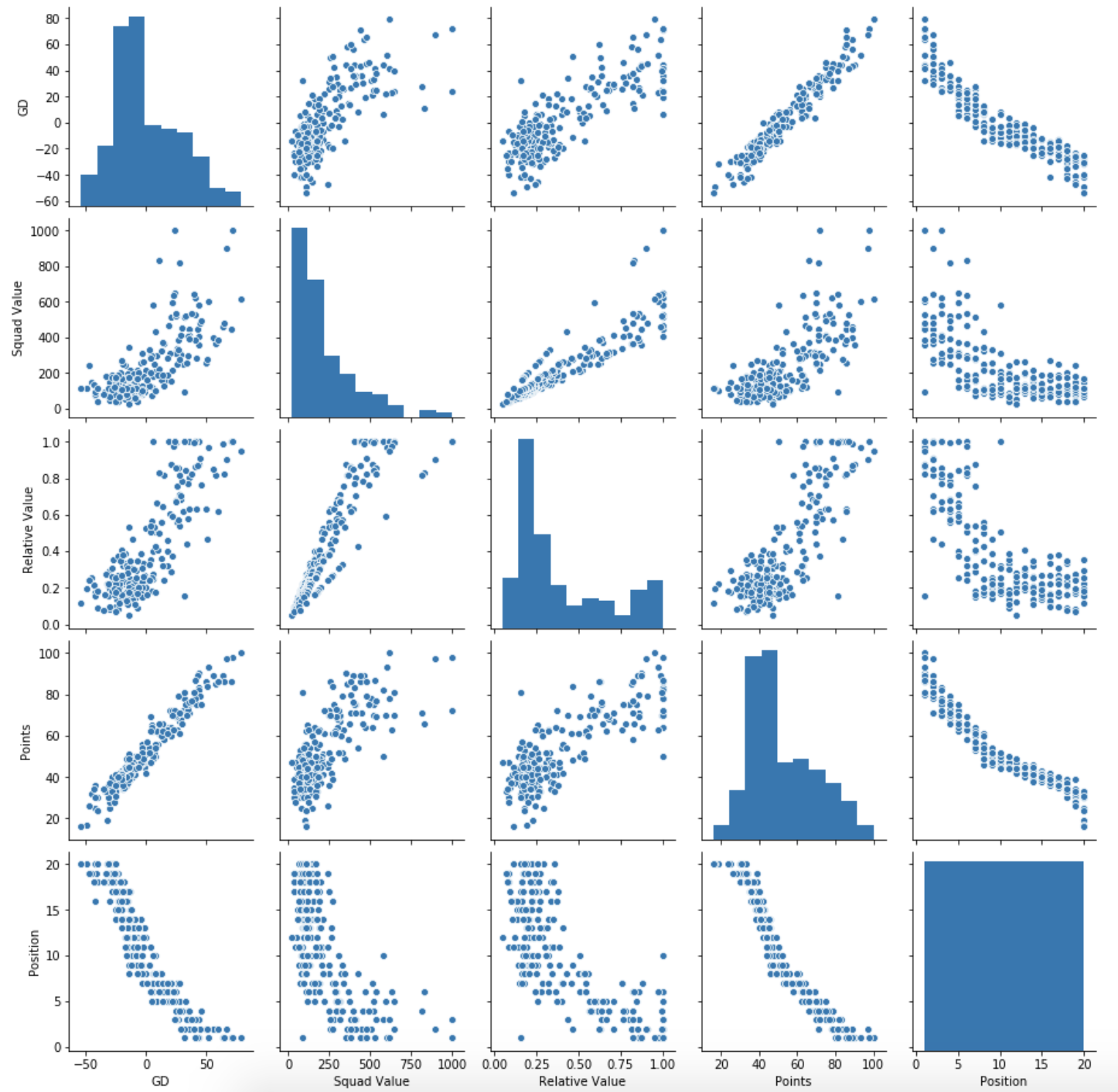
Looks quite similar to the squad value relationships in many parts, but looks to have a stronger correlation with points and goal difference. Hopefully this will give us a more accurate model. Let’s create a new one in the same way as above
#Assign relevant columns to variables and reshape them
X = data['Relative Value']
y = data['Points']
X = X.values.reshape(-1,1)
y = y.values.reshape(-1,1)
#Create training and test sets for each of the two variables
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=101)
#Create an empty model, then train it against the variables
lm = LinearRegression()
lm.fit(X_train,y_train)
And we’ll again look at the coefficient to see what our model tells us to expect. We’ll divide it by 10, to see how many points increasing our squad value by 10% of the most expensive team should earn
print(lm.coef_/10)
predictions = lm.predict(X_test)
plt.scatter(X_test, y_test, color='purple')
plt.plot(X_test, predictions, color='green', linewidth=3)
plt.title("Relative Squad value vs points - Model Two")
plt.show()
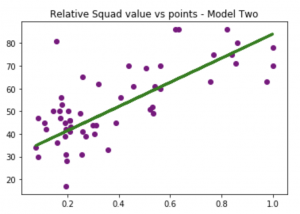
The model predicts just over 5 points. This seems to make sense, as the difference between top and bottom would often range around 53 or so points.
So for every 10% that you are off of the most expensive team, our model suggests that you should expect to drop 5.3 points.
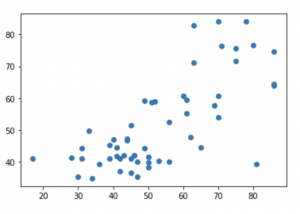
Let’s run the same tests as before to check out whether or not this new model performs better. Firstly, the same two charts – the scatter plot & the distribution of the errors. The scatter plot looks to to have more of a correlation and the distribution also is a bit tighter, with fewer big errors.
plt.scatter(y_test,predictions)
plt.title('How many points out is each prediction?')
sns.distplot((y_test-predictions),bins=50,color='purple');
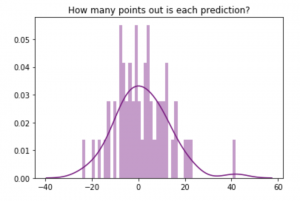
To back up the eye test, we’ll use our mean absolute error metric – the average difference between the prediction and the truth. Our previous metric was 9.7…
print('MAE:', metrics.mean_absolute_error(y_test, predictions))
So that’s nearly an 8% improvement… not a gamechanger, but I think we can agree that this model makes more sense than the one before. Not only does it fit better (correlation between predictions/reality also increased significantly), but we know from our own knowledge of football that transfer fees and market values have hugely inflated over the length of our dataset.
There are other oddities that you will have noticed, such as the extreme outliers (Leicester 15/16, Chelsea 15/16, Chelsea 18/19), the cluster of teams around the relegation places. All of these could do with their own further analysis, but that is beyond the scope of this tutorial. Would make for a really interesting piece itself if you fancy trying your hand at this!
Summary
That just about covers off our simple linear regression 101 – let’s summarise what we learned.
1) Simple linear regression is an approach to explaining how one variable may affect another.
2) We built a model where we see how squad value affects points.
3) We observed what the model suggested and saw how many points an extra million spent might gain.
4) We checked the validity of the model and saw what the average error was.
5) We repeated the above with another (new) metric to create an improved model, reducing the error.
Great effort making it this far. For developing these concepts, you may want to gather data from other leagues to see if squad value is as closely related to winning as it is here. Otherwise, with aggregated event data, you could look to see how reliable shots or passes are as goal predictors.
As for building your stats model knowledge, take a read on multiple linear regressions and we will look to have an article up on this topic soon!
Any questions, you’ll find us on Twitter @fc_python.